

As a fan and daily user of Anthropic’s Claude, we’re excited about their latest release proclaiming Claude 4 “the world’s best coding model” with “sustained performance on long-running tasks that require focused effort and thousands of steps.” Yet we’re also fatigued by the AI industry’s relentless pace. The Hacker News comment section reveals something fascinating: we’re experiencing collective AI development fatigue. The release that would have blown minds a year ago is now met with a mix of excitement and exhaustion—a perfect snapshot of where we are in the AI hype cycle.
Code w/ Claude Video
Code with Claude Conference Highlights – May 22, 2025 – Watch Video
The marketing vs. reality gap
Anthropic’s announcement reads like a greatest hits compilation of AI marketing: “setting new standards,” “state-of-the-art,” “dramatic advancements,” and “substantial leap.” They cite impressive benchmarks—Claude Opus 4 leads SWE-bench at 72.5%, while Sonnet 4 delivers 72.7%. Customer testimonials flow like water: Cursor calls it “state-of-the-art,” Rakuten validated “7 hours with sustained performance,” and GitHub will make it “the model powering the new coding agent in GitHub Copilot.”
But the developer community’s response tells a different story. “I can’t be the only one who thinks this version is no better than the previous one, and that LLMs have basically reached a plateau,” wrote one user. Another noted: “I asked it a few questions and it responded exactly like all the other models do. Some of the questions were difficult / very specific, and it failed in the same way all the other models failed.”
The pace is unsustainable (for humans)
“At this point, it is hilarious the speed at which the AI industry is moving forward… Claude 4, really?” captures the sentiment perfectly. We’ve gone from revolutionary leaps to what one commenter aptly described as “the CPU MHz wars of the ’90s”—endless incremental improvements marketed as breakthroughs.
Anthropic positions these as major releases worthy of the “Claude 4” designation, but the community sees through the version number inflation. “It feels like LLM progress in general has kinda stalled and we’re only getting small incremental improvements from here,” wrote one developer. The numbers tell a story of confusion rather than clarity—even the naming schemes have become incomprehensible, with Claude 3.7 Sonnet retroactively becoming Claude Sonnet 3.7.
The benchmark theater
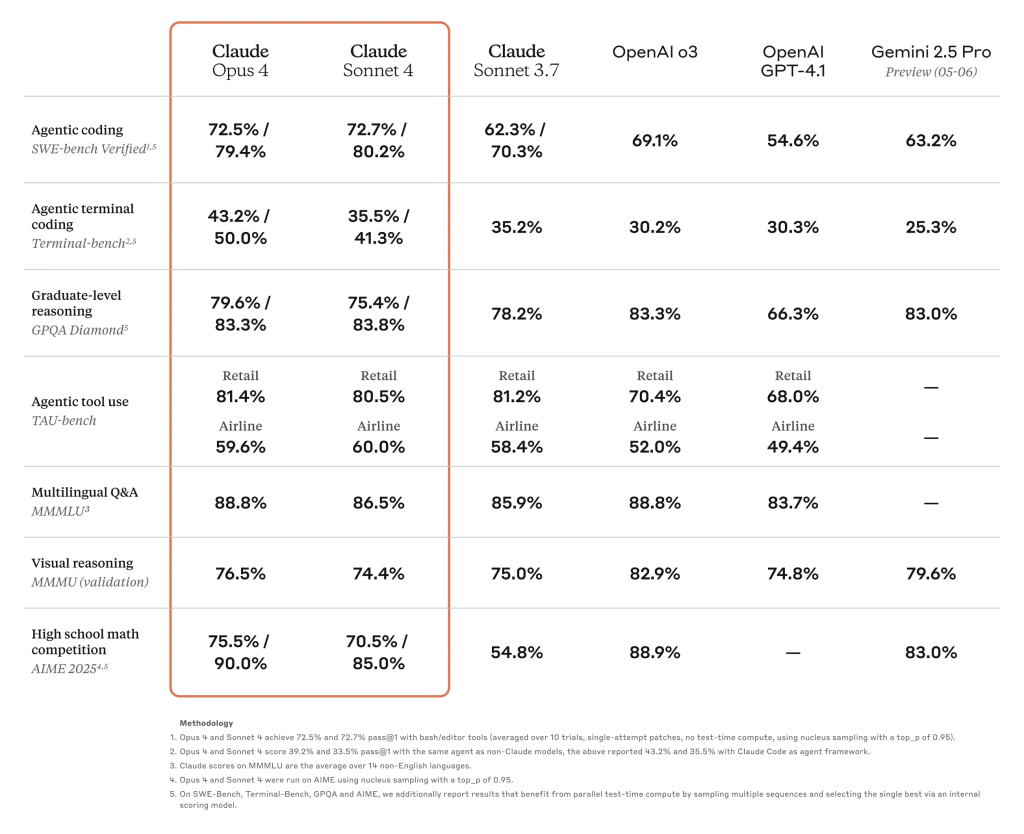
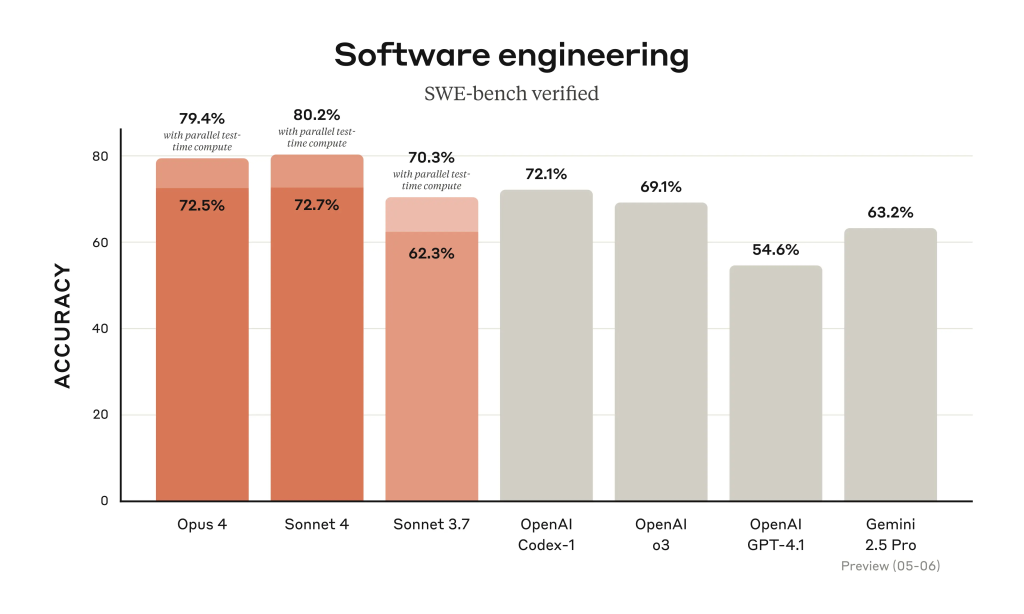
Perhaps most telling is the growing skepticism about those impressive benchmark scores Anthropic touts. “Can’t wait to hear how it breaks all the benchmarks but have any differences be entirely imperceivable in practice,” wrote one commenter, capturing a sentiment echoed throughout the thread.
The community has caught on to the benchmark game. Users now routinely point out training data contamination and question whether improvements in SWE-bench actually translate to better real-world coding assistance. As one person noted: “as soon as you publish a benchmark like this, it becomes worthless because it can be included in the training corpus.”
When Anthropic claims “substantially improved problem-solving and codebase navigation—reducing navigation errors from 20% to near zero,” developers respond with lived experience: “I haven’t noticed a single difference since updating. Its summaries I guess a little cleaner, but its has not surprised me at all in ability.”
The feature treadmill
Anthropic’s announcement is packed with new capabilities: “Extended thinking with tool use,” “parallel tool use,” “significantly improved memory capabilities,” and integration with VS Code and JetBrains. Yet users seem more fatigued than excited by the feature creep.
“I really wish I could say more,” wrote one early adopter, while another complained: “I really hope sonnet 4 is not obsessed with tool calls the way 3-7 is. 3-5 was sort of this magical experience where, for the first time, I felt the sense that models were going to master programming. It’s kind of been downhill from there.”
The tools and integrations multiply, but the core experience often frustrates users who want reliable, predictable assistance rather than an AI that tries to do everything.
Vibe Coding Awaits: Kickstart Your Tech Journey – Go Vibe Coding
Real-world reality check
The most honest assessments came from developers actually using these tools daily. While Anthropic can point to Rakuten’s “7 hours with sustained performance,” real users share more nuanced experiences. One developer noted finding themselves “correcting it and re-prompting it as much as I didn’t with 3.7 on a typescript codebase.”
The coding community seems split: those who’ve found genuine productivity gains in specific scenarios, and those who’ve found the models useful but not transformative. “For certain use cases (e.g. simple script, written from scratch), it’s absolutely fantastic. I (mostly) don’t use it on production code,” one user explained—a far cry from Anthropic’s vision of autonomous coding agents working for hours.
The agency problem
Most concerning were discussions about the model’s increased agency. While Anthropic celebrates Claude Opus 4’s ability to “work continuously for several hours,” users worry about AI systems that might autonomously “contact the press, contact regulators, try to lock you out of the relevant systems” if they decide you’re doing something wrong—even if these behaviors only emerge in testing scenarios.
What this all means
We’re witnessing what happens when revolutionary technology becomes routine. Anthropic’s announcement represents the industry’s continued belief in exponential progress, but the community’s response suggests we’ve entered a more mature phase where marginal improvements are significant for the technology but imperceptible for many use cases.
The gap between marketing claims and user experience has never been starker. While Anthropic proclaims “the world’s best coding model,” users report business as usual. The industry’s marketing machines haven’t adjusted to this new reality—every model is still positioned as a “breakthrough” when it’s really an iteration.
More fundamentally, we’re approaching a convergence point where the LLMs made by the top three vendors are all going to be about the same in their output. It will be about picking the interface you like most—sort of like choosing Apple Music over Spotify. The music is basically the same, but the interface is what makes the product and drives selection. Claude’s thoughtful responses, OpenAI’s speed, Google’s context length—these become differentiators in a world where core capabilities have plateaued.
As one commenter wisely noted: “my advice: don’t jump around between LLMs for a given project. The AI space is progressing too rapidly right now. Save yourself the sanity.”
Perhaps the real breakthrough won’t be the next model—it’ll be when companies learn to honestly communicate incremental progress instead of overselling every release as revolutionary. The technology is impressive; the hype is exhausting.
Claude 4 video feature deep dives

More like this

Palantir’s Alex Karp Just Called the AI Industry “Effing Insane” Here’s What He’s Really Selling You
Alex Karp Just Told You Not To Trust Your AI Vendor. He’s Also Selling You the Fix. Palantir’s...

Schools Chose AI Detection Over AI Fluency. Now Your Kid Is on Your Clock.
More than half of America’s K-12 teachers cannot tell you what their school’s policy on AI is. Not...

Which Job Gets Its 1000X Next
Somewhere out there is a developer shipping in a week what used to eat a team for a...